우선순위 큐 (Priority Queue)
Queue는 알다시피 FIFO(First In First Out, 선입선출)형식의 자료구조이다.
우선순위 큐는 이런 큐에 우선순위의 개념을 도입한 것이다.
즉, 우선순위가 높은 것이 먼저 나가는 자료구조이다.
[ 우선순위 큐 ADT ]
우선순위 큐에서 가장 중요한 연산은 insert 연산(요소 삽입) 과 delete 연산(요소 삭제) 이다.
- 객체 : n개의 element형의 우선 순위를 가진 요소들의 모임
- 연산 :
- create() : 우선순위 큐를 생성한다.
- init(q) : 우선순위 큐 q를 초기화 한다.
- is_empty(q) : 우선순위 큐 q 가 비어있는지 검사한다.
- is_full(q) : 우선순위 큐 q가 가득 찼는가 검사한다.
- 🌟 insert(q,x) : 우선순위 큐 q에 요소 x를 추가한다.
- 🌟 delete(q) : 우선순위 큐로부터 가장 우선순위가 높은 요소를 삭제하고 반환한다.
- find(q) : 우선순위가 가장 높은 요소를 반환한다.
삽입의 순서와 상관없이 삭제 순서는 데이터의 우선순위에 따라 결정된다.

[ 우선순위 큐 구현 방법 ]
우선순위 큐는 배열, 연결 리스트 등의 여러 가지 방법으로 구현이 가능하다.

그 중 가장 효율적인 구조는 힙(heap)이다. 나는 힙을 중점으로 다뤄보도록 하겠다.
[ 힙(Heap) ]

힙, 히프는 완전 이진 트리의 일종으로 우선순위 큐를 위하여 특별히 만들어진 자료구조이다.
힙은 완전 정렬된 상태가 아닌 느슨한 정렬 상태를 유지한다.
여러 개의 값들 중에서 가장 큰 값이나 가장 작은 값을 빠르게 찾아내도록 만들어진 자료구조이다.
부모 노드의 키 값이 자식 노드의 키 값보다 항상 큰 완전 이진트리를 말한다.
최대 히프(Max Heap)
key(부모노드) >= key(자식노드)
최소 히프(Min Heap)
key(부모노드) <= key(자식노드)
히프는 중복된 값을 허용함에 유의해야한다.
느슨한 정렬 상태
위에서 언급한 느슨한 정렬 상태는 큰 값이 상위 레벨에 있고 작은 값이 하위레벨에 있다는 정도를 뜻한다.
히프의 목적이 삭제 연산이 수행 될 때마다 가장 큰 값을 찾아내기만 하면 되는 것이므로(가장 큰 값은 루트노드) 전체를 정렬할 필요가 없다.
구현 방법

왼쪽 자식의 인덱스 = 부모의 인덱스 * 2
오른쪽 자식의 인덱스 = 부모의 인덱스 *2 + 1
부모의 인덱스 = [자식의 인덱스 / 2]
삽입 연산(unheap 연산)
1. 힙에 새로운 요소가 들어오면, 일단 새로운 노드를 힙이 마지막 노드에 이어서 삽입
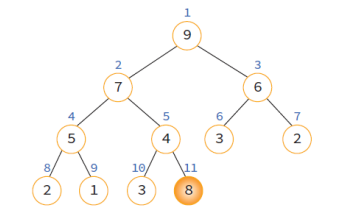
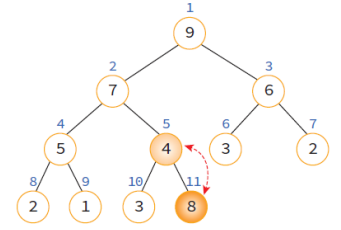
2. 삽입 후 새로운 노드를 부모 노드들과 교환하여 힙의 성질 만족
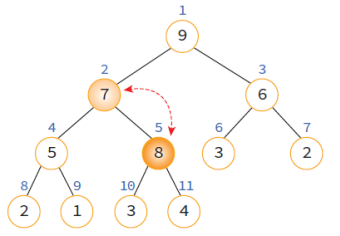
삭제 연산(downheap 연산)
1. 루트 노드를 삭제
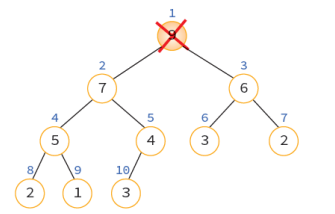
2. 마지막 노드를 루트 노드로 이동
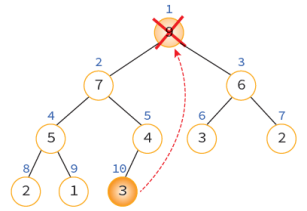
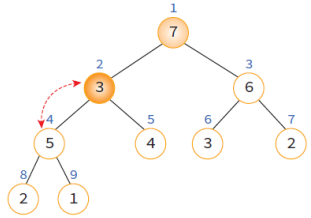
3. 루트에서 단말 노드까지의 경로에 있는 노드들을 교환하여 힙의 성질 만족

📖 참고 자료
경상대학교 자료구조 수업 - 오범석교수님
'Computer Science 📑' 카테고리의 다른 글
| [Data Structure/자료구조] CS 질문 정리 (0) | 2023.03.16 |
|---|---|
| 암호화 알고리즘 (0) | 2023.03.08 |
| [DB/데이터베이스] 저장 프로시저(Stored Procedure) (0) | 2023.02.21 |
| [DB/데이터베이스] Clustering / Replication / Sharding (0) | 2023.02.13 |
| [DB/데이터베이스] RDB와 NoSQL의 Replicaiton / Clustering 방식 (0) | 2023.02.13 |




댓글