728x90
데이터베이스는 기본적으로 하나의 서버, 하나의 스토리지를 가지고 있다.
Clustering
🤷♂️ 데이터 베이스 서버가 죽으면?
🙋♀️ 서버를 여러개로 만들자!(클러스터링)
- 여러 개의 DB를 수평적인 구조로 구축하는 방식
- 분산 환경을 구성하여 Single point of failure와 같은 문제를 해결할 수 있는 Fail Over 시스템을 구축하기 위해서 사용
- 동기 방식으로 노드들 간의 데이터를 동기화
single point of failure(단일 장애점,SPOF)
시스템 구성 요소 중에서, 동작하지 않으면 전체 시스템이 중단되는 요소가 이중화가 되어 있지 않다면 SPOF일 가능성 높음
Fail over
실 운용환경(컴퓨터 서버, 시스템, 네트워크) 등에서 이상이 생겼을 때, 대체 작동 또는 장애 극복(조치)을 위해 예비 운용환경으로 자동전환되는 기능
1. Active & Active
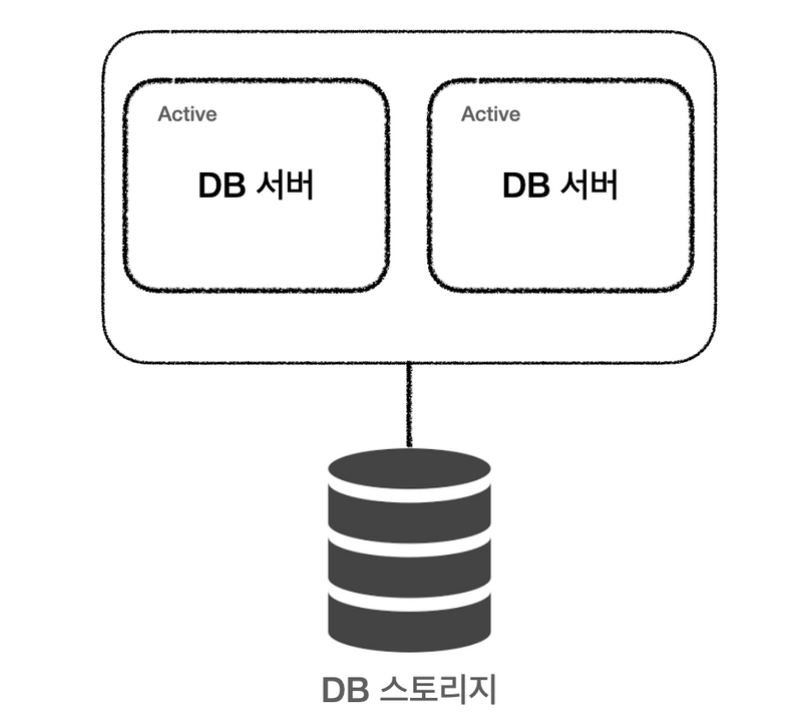
- 서버 한대가 죽더라도 하나의 서버가 동작하고 있어서 서비스에 큰 문제 X
- 다른 서버가 동작하는 동안 복구를 하여 서비스의 중단 없음
- 하나의 데이터베이스에 가해지는 부하가 두개로 나눠지므로 CPU, Memory 부하도 줄어듦
- 여러 개의 서버가 하나의 스토리지 공유하기 때문에 병목현상 발생
2. Active & Stand-By
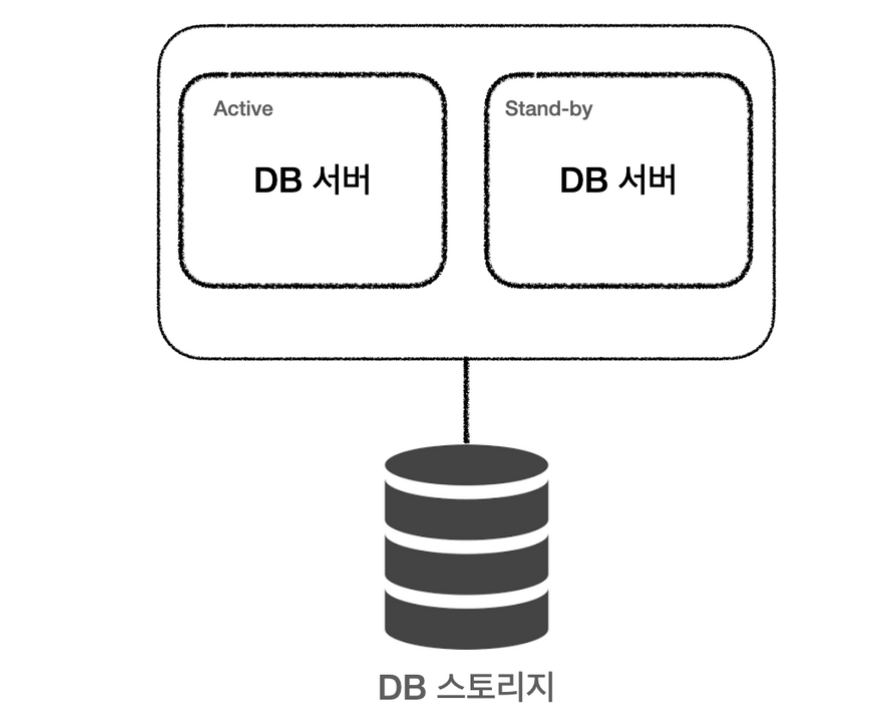
- Active 상태의 서버에 문제가 생겼을 때 Fail over를 하여 Stand-by 서버를 Active로 전환하여 문제에 대응
- Fail over가 발생하는 시간동안에는 서비스가 중단될 수 밖에 없음
- 결론적으로 한 대만 운영 -> 효율은 Active&Active의 절반
- 비용이 저렴 (standby는 실제로 운용되지 않기 때문)
Replication
🤷♂️ 저장된 데이터가 손실되면 어쩌지?
🙋♀️ 실제 데이터가 저장되는 저장소도 복제하자!(레플리케이션)
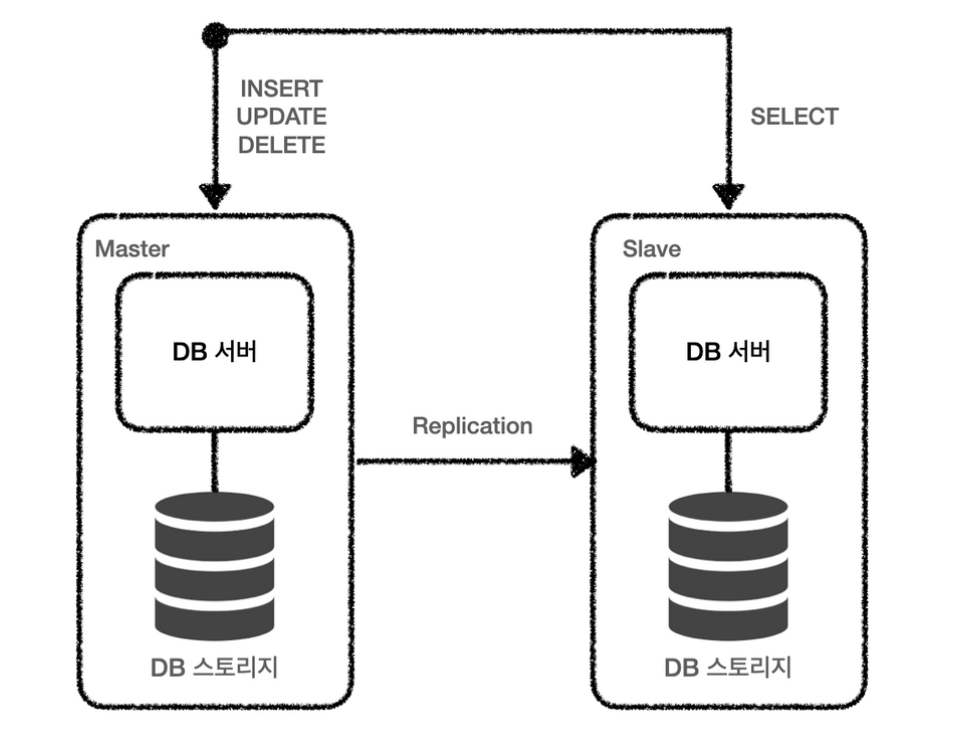
- 데이터베이스 스토리지 복제
- 데이터베이스 서버를 확장한 Clustering과 달리 서버와 스토리지 모두 확장
- 여러 개의 DB를 권한에 따라 수직적인 구조(Master-Slave)로 구축하는 방식
- Master : INSERT, UPDATE, DELETE
- Slave : SELECT
- Slave 서버 여러개를 통해 분산하여 처리할 수 있어 성능 향상에 도움이 된다.
- 버전 관리 필요, 적어도 Slave가 상위버전
- 비동기방식으로 데이터 동기화하기 때문에 일관성있는 데이터 얻지 못 할 수 있음
- 동기 방식으로 Replication할 수 있지만, 속도가 느려짐
- Master 서버가 다운되면 복구 및 대처 까다로움
현재는 master-slave 단어를 안쓰는 추세인 만큼 source-replica 구조로 불리기도 함.
구축 목적
- 스케일 아웃
- 갑자기 늘어나는 트래픽에 대해 부하를 줄이기 위해 서버를 늘리는 것
- 데이터 백업
- 백업 과정은 실제 실행중인 쿼리에 영향을 줄 수 있다.
- => 레플리카 서버에서 데이터 백업을 진행
- 데이터 분석
- 데이터 분석의 경우, 대량의 데이터 조회, 복잡한 쿼리가 많을 수 있다.
- 소스 서버에서 데이터 분석을 할 경우, 실제 서비스에 문제가 생길 수 있다.
- => 데이터 분석 전담 서버를 두는 것이 좋다.
- 데이터의 지리적 분산
- 데이터베이스 서버가 멀리 떨어져 있다면 빠른 응답을 받기 어렵다.
- 다양한 지역에 레플리카 서버를 두어 응답 속도를 높일 수 있다.
Sharding
🤷♂️ 데이터가 많아서 검색이 느린데 더 빠르게 할 수 있는 방법이 있을까?
🙋♀️ 테이블을 나눠서 검색하자! (샤딩)
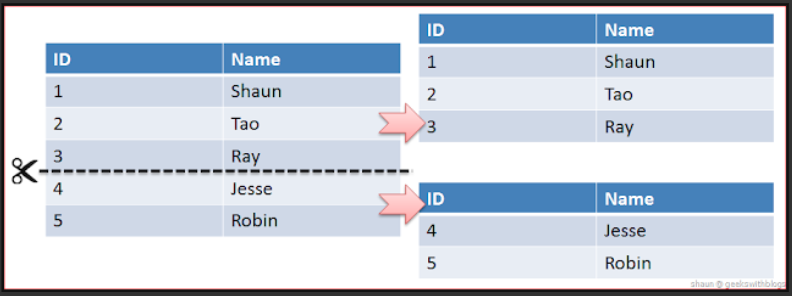
- 같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법
- 테이블을 특정 기준으로 나눠서 저장 및 검색
- Sharding Key : 나눠진 Shard 중 어떤 shard를 선택할 지 결정하는 키, 결정방식에 따라 Sharding 방법이 나누어짐
Shard Key 결정 방식
Hash Sharding

- Shard Key : Database id를 Hashing 하여 결정
- Hash크기는 Cluster안에 있는 Node개수로 정하게 됨
- 구현이 간단하다(key-value)
- 확장성이 떨어진다
- Node개수를 늘리거나 줄일 경우, Hash 크기와 Key가 변함 -> Data 분산 Rule 어긋남
- => Resharding 필요
- 공간에 대한 효율을 고려하지 않는다
Dynamic Sharding

- 확장에 용이하다
- Node의 개수를 늘릴 경우 : Locatoer Service에 Shard Key 추가만 하면 됨
- 기존 Data Shard Key 변경 X
- 데이터를 재배치 시 Locator Service의 Shard Key Table도 동기화 해야한다.
- Locator Service를 통해 Shard Key를 얻는다.
- Locator에 의존적이다.
- Locator가 성능을 위해 Cache하거나 Replication할 경우, 잘못된 Routing을 통해 Data 찾지 못하고 Error 발생
- ex ) HDFS : Name Node, MongoDB : Config Server
- 위의 두가지 방법은 Key-Value 형태를 지원하기 위해 나온 방법
Entity Group

- Key-Value가 아닌 다양한 객체로 구성된 경우 Applicaiton의 복잡도를 줄이는 방향으로 Sharding하는 방법
- 관계가 있는 Entity끼리 같은 Shard 내에 공유하도록 만든 방식
- 단일 Shard 내에서 쿼리가 효율적
- 단일 Shard 내에서 강한 응집도를 가진다
- 다른 Shard의 Entity와 연관되는 경우 비효율적
- 사용자가 늘어남에 따라 확장성이 좋은 Partitioning
- cross-partition 쿼리는 single partition 쿼리보다 consistency의 보장과 성능을 잃음
❓ 관련 질문
Q. 데이터베이스 클러스터링과 리플리케이션의 차이에 대해 설명해주세요.
Q. mongoDB에서 Config Server에 저장된 metadata는 무엇인가요?
Q. Replication의 구축목적은 무엇인가요?
📖 참고 자료
MySQL 클러스터링을 위한 Galera Cluster
728x90
'Computer Science 📑' 카테고리의 다른 글
| [Data Structure/자료구조] 우선순위 큐(Priority Queue) & 힙(Heap) (0) | 2023.02.27 |
|---|---|
| [DB/데이터베이스] 저장 프로시저(Stored Procedure) (0) | 2023.02.21 |
| [DB/데이터베이스] RDB와 NoSQL의 Replicaiton / Clustering 방식 (0) | 2023.02.13 |
| [OS/운영체제] CS 질문 정리 (0) | 2023.02.07 |
| [OS/운영체제] 메모리 계층(Memory Hierarchy) (4) | 2023.01.29 |




댓글