728x90
MySQL 사용 시(RDB)
[ clustering ]
Tungsten, MySQL Replicaiton, NDB, Galera 등 존재
그 중 Galera Clustering에 대한 소개
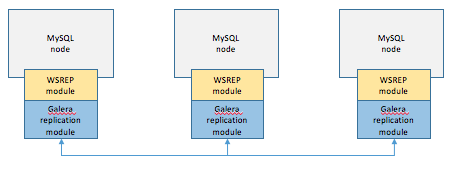
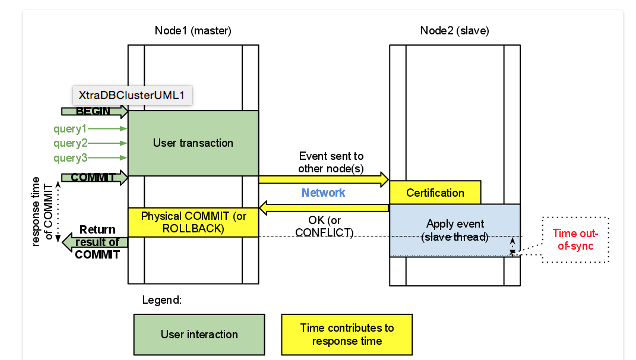
처리순서
- 1개의 노드에 쓰기 트랜잭션이 수행되고, COMMIT을 실행한다.
- 실제 디스크에 내용을 쓰기 전에 다른 노드로 데이터의 복제를 요청한다.
- 다른 노드에서 복제 요청을 수락했다는 신호(OK)를 보내고, 디스크에 쓰기를 시작한다.
- 다른 노드로부터 신호(OK)를 받으면 실제 디스크에 데이터를 저장한다.
- WSREP 모듈 : 데이터베이스에 복제를 위한 범용 모듈- 데이터가 전체 노드에 일관성있게 저장됨
- 모든 노드가 마스터 노드로 작동하며, 특정 노드에 장애가 나더라도 서비스에 큰 문제 없음
- MySQL Replication의 경우 마스터 노드가 장애가 나면 슬레이브 노드 중 하나를 마스터로 승격해야하는 등 운영 프로세스가 복잡
- 데이터 디스크 저장 전, 모든 노드에 데이터 복제 요청을 보내기 때문에 replication에 비해 쓰기 성능이 떨어짐
- LOCK 문제가 생기거나 슬로우 쿼리 들이 많이 발생할 때 장애를 다른 노드로 전파시킬 가능성 높음
- 하나의 클러스터에서 유지할 수 있는 노드의 수에 한계가 있어(전체 노드가 많아지면 시간 오래걸리기 때문), 횡적 스케일링의 한계 올 수 있음
[ replication ]
MySQL Replication
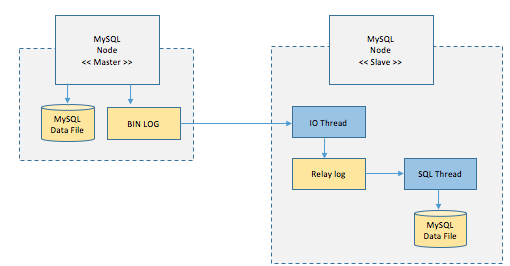
처리순서
- Master node는 데이터를 저장하고, 트랜잭션에 대한 로그 BIN LOG에 저장(시간 순)
- Slave node는 BIN LOG 복사(IO Thread가 수행)
- Replay Log에 기록됨
- SQL Thread가 읽어와 하나씩 수행하여 Data File에 저장- master / slaves 로 구성 (single point of failure 해결)
- master DBMS : 웹서버로 부터 데이터 등록/수정/삭제 요청시 바이너리로그(Binarylog)를 생성하여 Slave 서버로 전달 (DML 처리만 수행)
- slave DBMS : Master DBMS로 부터 전달받은 바이너리로그(Binarylog)를 데이터로 반영 (read만 수행, 여러대 가능)
- 특정 노드는 쓰기를 담당하고, 나머지는 읽기 담당
- 방식이 단순하여 신뢰도 높음
- 데이터 복제가 동기방식이 아닌 비동기방식, master node에 적용한 데이터 변경사항이 slave에 반영될 때까지 일정시간 걸림 => 일시적 데이터 불일치성 발생 가능
MongoDB 사용 시(NoSQL)
[ clustering ]
Sharded cluster
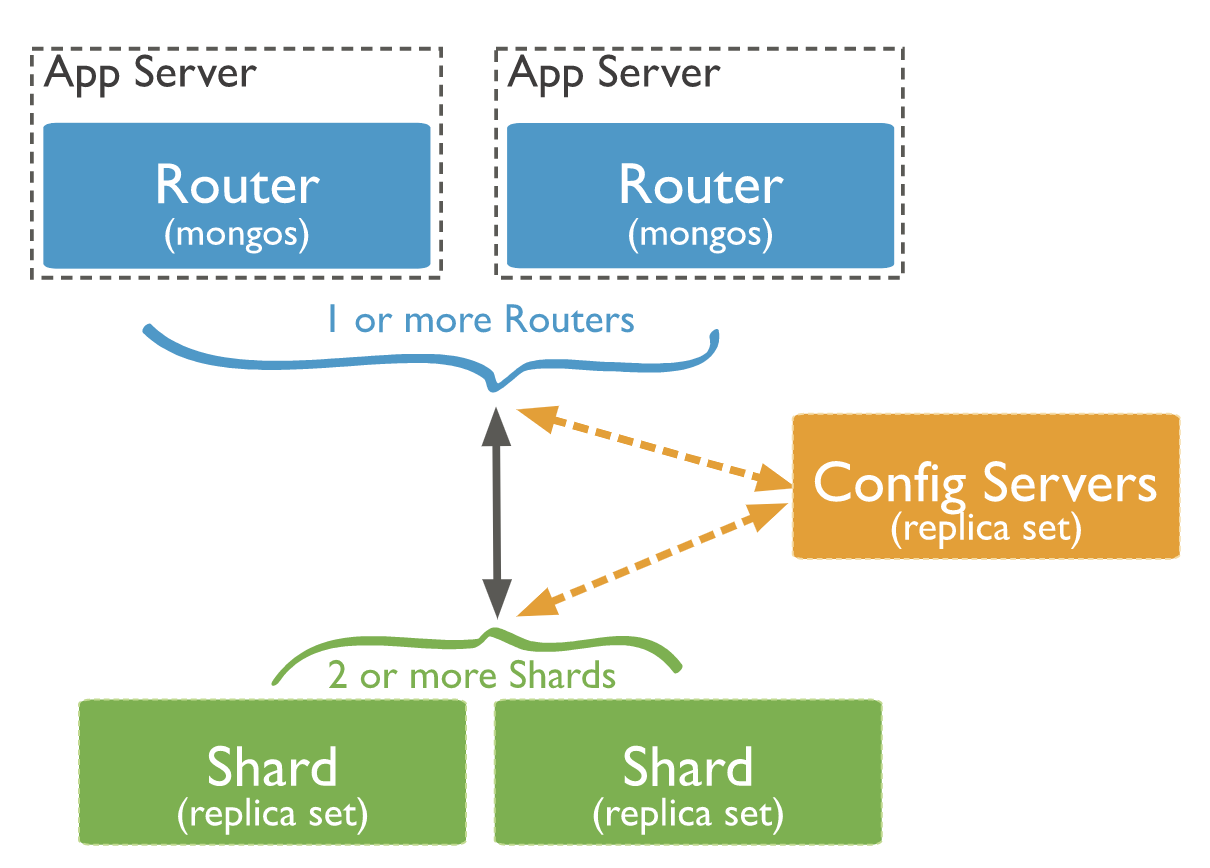
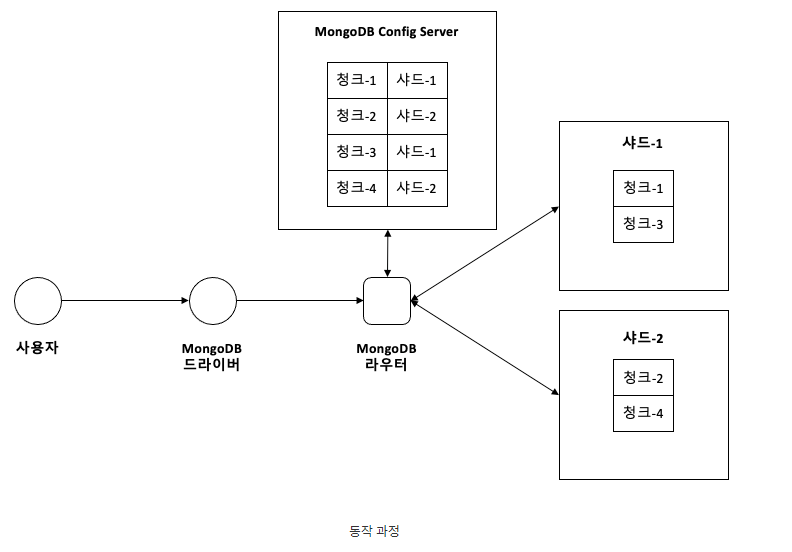
처리과정
- 쿼리가 참조하는 컬렉션의 Chunk metadata를 Config Server로부터 가져와 router의 메모리에 캐시한다.
- 쿼리의 조건에서 Sharding Key 조건을 찾는다.
- 1) Sharding Key 존재할 경우 : 해당 Sharding Key가 포함된 Chunk 정보를 router의 캐시에 검색하여 Shard서버로만 사용자 쿼리를 요청
- 2) Sharding Key 없을 경우 : 모든 Shard 서버로 쿼리를 요청한다.
- 쿼리를 전송한 대상 Shard 서버로부터 쿼리 결과가 도착하면 결과를 병합하여 사용자에게 결과를 반환한다.- Mongodb는 직접 특정 Shard에 접근할 수 없음
- Query Router에 명령을 하고, Query Router가 Shard에 접근하는 방식(Config Server정보기반으로 data chunk 위치를 찾아가는 것도 이때 수행됨)
- query router : 쿼리를 받아 각 샤드로 보내주는 역할, 데이터 저장되어 있진않고 router 역할만 수행
- shard : 실제 데이터가 저장되는 저장소
- config : 어떤 shard가 어떤 데이터(data chunk)를 가지고 있는지, data chunk들을 어떻게 분산해서 저장하며 관리하라 지 알 수 있음
- 성능 문제를 위해 shard 여러개를 두고 분산처리
- scaling을 통해 늘리고 즐일 수 있음
- 보통 3개의 shard 구성(SPOF막기위해)
- Query Router는 Shard정보를 찾는 부분의 성능을 위해 Config Server의 metadata를 cache로 저장해둔다.
- metadata : 데이터가 저장되어 있는 shard 정보 및 sharding key 정보
[ replicaiton ]
replica-set

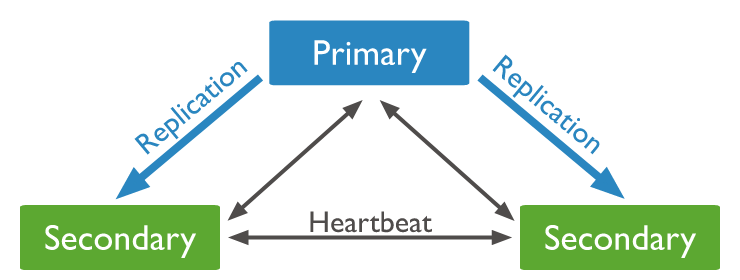
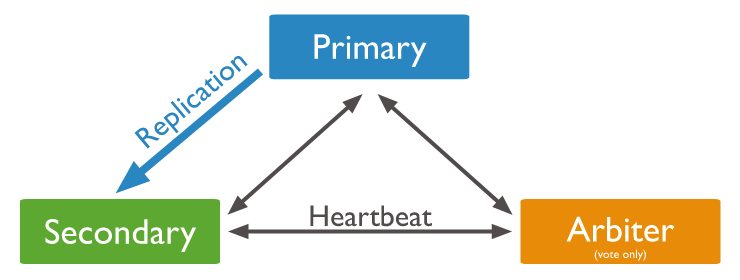
- Primary node / Secondary node 로 구성
- Primary node : 모든 쓰기 작업 수행, 기본적으로 읽기 작업도 Primary 몫
- 노드 간 heartbeat을 통해 상태체크
- Primary node 사용할 수 없는 경우(장애나 네트워크 이슈) 적격한 Secondary node는 새로운 Primary 노드 선택을 위한 투표 개최 => 홀수 노드 구성이 좋다
- 짝수로 구성하게 되면 홀수로 구성한 경우와 다르지 않아 서버 낭비로 이어짐, 쿼럼(Quorum) 구성이 어려울 수 있음
- Arbiter 모드 : Primary node 선출을 위한 투표만 참여, 디스크 저장X, 하나 이상 필요 X
❓ 관련 질문
Q. 데이터베이스 클러스터링과 리플리케이션의 차이에 대해 설명해주세요.
Q. mongoDB에서 Config Server에 저장된 metadata는 무엇인가요?
Q. Replication의 구축목적은 무엇인가요?
📖 참고 자료
MySQL 클러스터링을 위한 Galera Cluster
728x90
'Computer Science 📑' 카테고리의 다른 글
| [DB/데이터베이스] 저장 프로시저(Stored Procedure) (0) | 2023.02.21 |
|---|---|
| [DB/데이터베이스] Clustering / Replication / Sharding (0) | 2023.02.13 |
| [OS/운영체제] CS 질문 정리 (0) | 2023.02.07 |
| [OS/운영체제] 메모리 계층(Memory Hierarchy) (4) | 2023.01.29 |
| [OS/운영체제] 운영체제란 (0) | 2023.01.28 |




댓글