🙋♀️ 공부하는 과정에 있습니다. 틀린 부분에 대한 지적은 언제든 환영합니다.
CPU 스케줄링 알고리즘
Q. 에이징( Aging)?
우선순위나 어떠한 이유로 자원을 점유하지 못하지만 시간이 지날수록 우선순위가 높아져 결국은 자원을 점유하게 만드는 기법
Q. 기아(Starvation)?
작업을 하기 위해 프로세스가 자원을 할당받아야하는데 우선순위나 어떠한 이유로 자원을 점유하지 못한 상태로 계속 대기하는 것
Q. SJF를 preemptive(선점)한 방식으로 구현하기 위해서는 ready queue에 새로운 프로세스가 도착할 때마다 CPU에게 interrupt를 걸어야하나요?
preemptive SJF는 새로운 프로세스가 도착하면, 도착한 프로세스의 CPU 시간(버스트 크기)과 현재 실행 중인 프로세스의 남은 CPU 시간을 비교하여 더 짧은 CPU 시간을 가진 프로세스를 수행 시킨다.
즉, 도착한 프로세스가 더 짧다면 CPU에 interrupt를 걸고, 아니라면 계속 진행한다.
( 인터럽트 → 현재 작업 중단 → 커널을 깨워 인터럽트 처리 → 원래의 작업으로 복귀 )
Q-1. 어떻게 새로운 프로세스가 도착했음을 알고, 그것이 더 짧은 프로세스임을 알고, CPU 제어권을 넘기는가요?
CPU 시간(버스트 크기)의 정확한 값을 사전에 아는 것은 사실상 불가능에 가깝다. 그렇기 때문에 예측(지수 평균)을 통해 진행한다. 새로운 프로세스가 더 짧은 프로세스일 경우, Dispatcher를 통해 CPU 스케줄러에 의해 선택된 프로세스에게 CPU의 제어권을 넘겨준다.
Q. Priority scheduling에서 우선순위를 정의하는 방식
프로세스의 의미(Sementic), 중요도를 기준으로 우선순위를 준다.
- 내부 : 제한 시간, 메모리 요구량, 열린 파일 수, 평균 I/O burst 비율, 평균 CPU burst 비율
- 외부 : 프로세스의 중요성, 사용료를 많이 낸 사용자, 작업을 지원하는 부서, 정책적 요인
이 있다.
Q. multilevel queue에서 우선순위 높은 queue의 프로세스가 끝나서 두번째 queue의 프로세스를 처리하던 중 첫번째 queue에 프로세스가 채워지면 preeptive하게 작동하는가요?
두번째 queue가 실행되려면 앞의 queue들이 다 비어있어야한다.
그렇기 때문에 두번째 queue를 처리하던 중 첫번째 queue가 채워지면 두번째는 잠시 뒤로 물러나고 우선순위가 높은 프로세스가 실행된다.(preemptive 방식)
Q. multilevel queue time slice방식에서 각 queue에 CPU time을 비율로 할당한다는 것의 의미는 무엇인가요? 어떤 것에 대한 비율인가요?
각 queue에 CPU time을 적절한 비율로 할당하는 것은 RR방식을 도입한 것이다.
각각의 큐에 다른 time quantum을 설정해주는 것을 의미한다.
예시로는 foreground queue의 RR에 80%를, background queue의 FCFS에 20%를 할당하는 것이 있다.
time quantum이 길어질수록 FCFS방식의 성격을 띄기 때문에 결국 우선순위가 낮은 background 프로세스에 상대적으로 더 긴 time quantum을 할당하여 FCFS 느낌이 된다.
교착상태(DeadLock)
Q. 데드락이 무엇인가요?
두 개 이상의 일련의 프로세스 혹은 스레드들이 서로가 가진 자원(resource)을 기다리며 block된 상태

자원 : 숫자 / 프로세스 : 자동차
Q. 데드락 발생조건 4가지
첫 번째는 상호배제(Mutual exclusion) 이다. 매 순간 하나의 프로세스만이 자원을 사용할 수 있다는 조건이다.
두 번째는 비선점(No preemption) 이다. 프로세스는 자원을 스스로 내어놓을 뿐 강제로 빼앗기지 않는다는 조건이다. 즉, 자원 반환은 오직 그 리소스를 취득한 프로세스만 할 수 있다.
세 번째는 점유 대기(Hold and wait) 이다. 자원을 가진 프로세스가 다른 자원을 기다릴 때 보유 자원을 놓지 않고 계속 가지고 있다는 조건이다.
네 번째는 순환 대기(Circular wait) 이다. 자원을 기다리는 프로세스가 간에 사이클이 형성되어야 한다는 조건이다.
Q. 데드락의 해결방법
예방(Deadlock Prevention), 회피(Deadlock Avoidance), 탐지 및 회복(Deadlock Detection and recovery), 무시(Deadlock Ignorance) 가 있다.
예방은 데드락 발생 필요 조건 중 어느 하나가 만족되지 않도록 하는 것이다. 가장 많이 사용하는 것은 순환 대기 조건을 만족시키지 않는 것이다.
회피는 실행환경에서 자원 요청에 대한 부가적인 정보를 이용해서 Deadlock의 가능성이 없는 경우에만 자원을 할당하는 것이다. (부가적인 정보 : 현재 사용 가능한 자원, 이미 할당된 자원, 앞으로 있을 자원 요청이나 반환 등)
탐지 및 회복은 말 그대로 Deadlock 발생은 허용하되 그에 대한 detection 루틴을 두어 Deadlock 발견 시 recover하는 것을 의미한다.
무시는 Deadlock을 시스템이 책임지지 않는 것이다. UNIX를 포함한 대부분의 OS가 채택한 방법이다.
인터럽트
Q. 인터럽트(interrupt)란 무엇인가요?
프로세서에 이벤트를 알려 현재 하던 명령의 위치를 저장 후 중단하고 다른 일을 하도록 처리하는 비동기적 방법을 뜻한다.
Q. 인터럽트 발생 시 처리 과정
- 실행중인 프로그램을 중단.
- 현재 프로그램 상태를 보관. (컨텍스트 스위칭 = 문맥 교환)
- 인터럽트 처리 루틴을 실행.
- 인터럽트 서비스 루틴을 실행.
- 인터럽트 요청 신호가 발생했을 때 보관한 PC의 값을 복원하여 이전 실행 위치로 복귀.
- 이어서 프로그램을 진행.
Q. 만약 필요한 데이터가 하드디스크에 있다면, CPU에서 바로 하드디스크에 접근해서 데이터를 가져오면 더 빠를텐데 왜 굳이 모든 계층구조를 모두 통해서 가져올까요?
프로그램의 실행은 지역적 특성을 띄고 있기 때문에 계층적으로 메모리를 두었을 때 더 성능이 좋아지기 때문이다.
즉, 모든 메모리의 역할이 피라미드 구조에서 자신보다 아래에 있는 메모리를 캐쉬하기 위해서 존재하는 것으로 이해해야 한다.
우리가 사용하는 시스템에서는 캐쉬 메모리가 높은 성능 향상을 가져다 준다.
그만큼 연산에 필요한 데이터가 캐쉬 메모리에 존재할 확률이 아주 높다는 뜻이다.
메인 메모리를 제외하고 L1캐쉬, L2 캐쉬에 연상에 필요한 데이터가 존재할 확률이 90%정도 된다.
하드디스크에서 데이터를 읽어들이는 빈도수는 전체 메모리 접근 빈도수의 불과 몇퍼센트밖에 되지 않는다.
결국 크게 보면 하드디스크에서 바로 접근하지 않는 것은 메모리의 지역성을 생각하여 나타난 현상이라고 볼 수 있다.
메모리 계층
Q. RAM을 주기억장치라고 표현하는 이유는 무엇인가요?
컴퓨터가 어떠한 프로그램을 실행하는 동작에 대해 설명해보겠다.
먼저 보조기억장치에서 주기억장치로 프로그램을 불러온다.(부팅, 로딩)
주기억장치에서 프로그램을 기억하고 CPU와 통신할 준비가 끝나면 CPU에서 데이터를 주고받으며 프로그램을 구동한다. (동작, 구동)
따라서 컴퓨터 입장에서는 RAM은 작업실, CPU는 작업자와 같은 역할을 하게 된다. 이런 역할 때문에 주기억장치라고 표한한다.
Q. 지역성에 대해 설명해 주세요.
- 지역성 : 데이터 접근이 시간적, 혹은 공간적으로 가깝게 일어나는 것
- 시간적 지역성(Temporal locality) : 특정 데이터가 한 번 접근되었을 경우,가까운 미래에 또 한 번 데이터에 접근할 가능성이 높음
- 공간적 지역성(Spatial locality) : 액세스 된 기억장소와 인접한 기억장소가 액세스 될 가능성이 높음
Q. 왜 불편하게 전원이 차단되면 모든 기억된 내용이 지워지는 휘발성 장치를 사용할까요?
아직 휘발성 특성, 단점을 가진 기계적 부품 이외에는 주기억장치의 역할을 할 부품이 상용, 양산화가 힘들기 때문이다.
빠른 속도와 효율을 제공해주기 때문에 휘발성임에도 불구하고 사용된다. 만일 기술의 발전으로 다른 방법이 생기면 이러한 단점이 사라질 수도 있다.
세그먼테이션
Q. 세그먼테이션은 무엇이고, 세그먼테이션으로 인해 어떤 장점이 있는지 설명하시오.
세그먼테이션은 가상 주소 공간을 세그먼트 단위로 실제 메모리 주소 공간에 독립적으로 각각 매핑하는 방식이다.
heap과 stack 사이의 사용하지 않는 비효율성 문제 해결
- [1] 더이상 메모리 공간이 낭비되지 않는다.
- [2] 이전보다 훨씬 더 많은 주소 공간을 지원할 수 있다.
- [3] 세그먼트는 주소 공간 간에 Code를 공유하면서 메모리를 절약할 수 있다.
Q. 세그먼테이션으로 주소변환 하는 방법에 대해 설명하세요.
가상 주소는 segment id + offset으로 구할 수 있다.
segment id는 상위 2개의 비트로 구분하고, offset은 하위 12개 비트로 계산한다.
segment id로 base 값을 찾고, offset을 계산하여 segmentation fault 발생 유무를 확인한다.
base값에 offset을 더하여 Physical memory 주소를 찾는다.
stack인 경우에는 base에 offset을 빼주어 주소를 찾는다.
Q. 세그먼테이션의 문제점과 해결방안은 무엇인지 설명하세요.
- 프로세스마다 크기가 모두 다르기 때문에 각 세그먼트의 크기도 모두 다르다. 그로 인해 외부 단편화(external fragmentaion) 문제가 발생한다.
- Compaction : 실제 메모리에 있는 기존의 세그먼트를 재배치시킨다. 하지만 Compaction 방법은 비용이 발생하여 성능이 떨어지는 문제점이 있다.
- Paging : 고정적인 크기(fixed-size)의 세그먼트로 외부 단편화를 제거하여 여유 공간을 관리할 수 있다. 그러나 페이징 기법 역시 내부 단편화(internal fragmentaion) 문제가 남아 있다.
페이징
Q.Paging(페이징)이 왜 나오게 되었고, 개념에 대해 말씀해주세요.
가변 크기 할당 방법인 segmentation의 외부 단편화 문제점을 해결하기 위하여 나왔다.
Paging은 프로세스의 가상 주소 공간을 고정적인 크기(fixed-sized)로 나누어서 메모리에 할당하는 방식이다.
(외부 단편화 : 남아있는 총 메모리 공간이 요청한 메모리 공간보다 크지만, 남아있는 공간이 연속적(contiguous)이지 않아 발생하는 현상)
Q.Paging의 장점과 단점에 대해 말씀해주세요.
- 장점 : 외부 단편화 문제 해결 / 페이지 공유 가능 (메모리 공간의 효과적 활용) / 페이지 보호 가능
- 단점 : 페이지 테이블 사용으로 분할방식 대비 주소결속에서 오버헤드 발생 (속도 저하) / 페이지 테이블의 메인메모리 저장으로 공간 낭비
Q. Paging을 이용한 주소 변환 과정에 대해 말씀해주세요. (Page table, PTE, PFN 개념 언급)
- 프로세스의 가상 주소로 VPN과 offset을 알아낸 뒤, 해당 프로세스의 VPN 값으로 프로세스의 page table에서 PTE 정보를 가지고 온다.
- PTE(page table entry)정보에서 PFN(page frame number)을 추출한다.
- PFN, offset을 사용해서 실제 메모리 주소를 얻는다.
PTE: page table에서 각 page의 정보
Page table: 가상 주소를 실제 메모리 주소로 매핑(변환)힐 때 사용되는 자료 구조
PFN: Physical Frame Number (= PPN, Physical Page Number)
Q. Context Switching은 무엇인가요?
Context Switching이란, CPU가 이전의 프로세스 상태를 PCB에 보관하고, 또 다른 프로세스의 정보를 PCB에서 읽어 레지스터에 적재하는 과정이다.
현재 진행하고 있는 Task(Process, Thread)의 상태를 저장하고 다음 진행할 Task의 상태 값을 읽어 적용하는 과정
Q. Context Switching의 진행 방법
- Task의 대부분 정보는 Register에 저장되고 PCB(Process Control Block)로 관리된다.
- 현재 실행하고 있는 Task의 PCB 정보를 저장한다. (Process Stack, Ready Queue)
- 다음 실행할 Task의 PCB 정보를 읽어 Register에 적재하고 CPU가 이전에 진행했던 과정을 연속적으로 수행할 수 있다.
Q. 프로세스의 Context Switching Cost의 해결방안은 무엇일까요?
여러 프로세스에 context switching을 하지 말고, 단일 프로세스에 여러 쓰레드를 생성하여 쓰레드에서 Context Switching을 하면 된다.
쓰레드의 경우, 메모리 공간을 공유하고 있어, 스택을 정리만 하면 되기 때문에 프로세스보다 비용이 적게 든다.
동기화
Q. 프로세스 동기화란?
다중 프로세스 환경에서 자원등에 한 프로세스만이 접근가능하도록 하는 것이다.
프로세스 동기화를 하지 않으면 데이터의 일관성이 깨지기 때문에 연산결과가 잘못 반환될 가능성이 존재하기 때문에 주의해야 한다.
Q. 동기와 비동기의 차이(블로킹, 넌블로킹)
동기/비동기는 두 개 이상의 무엇인가가 시간을 맞춘다/안맞춘다로 구분할 수 있다.
동기 방식은 메서드 리턴과 결과를 전달받는 시간이 일치하는 명령 실행 방식이다. 한 함수가 끝나는 시간과 바로 다음의 함수가 시작하는 시간이 같다.
비동기 방식은 여러 개의 처리가 함께 실행되는 방식으로, 동기 방식에 비해 단위시간 당 많은 작업을 처리할 수 있다.
단, CPU나 메모리를 많이 사용하는 작업을 비동기로 처리하게 되면 과부하가 걸릴 수 있다. 프로그램의 복잡도도 증가하게 된다.
블로킹/논블로킹은 동기/비동기와는 다른 관점으로, 내가 직접 제어할 수 없는 대상(IO/멀티스레드)을 상대하는 방법에 대한 분류이다.
블로킹 방식은 대상의 작업이 끝날 때 까지 제어권을 대상이 가지고 있는 것을 의미한다.
반면에 논블로킹은 대상의 작업 완료여부와 상관없이 새로운 작업을 수행한다.
동기 논블로킹은 계속해서 polling을 수행하기 때문에 컨텍스트 스위칭이 지속적으로 발생해 지연이 발생한다.
Q. 임계영역이 무엇인가요? 임계영역이 만족해야 하는 조건이 있나요?
- 키워드 : 상호 배제(Mutual exclution), 진행(Progress), 한정 대기(Bounded waiting)
공유 데이터의 일관성을 보장하기 위해 하나의 프로세스/스레드만 진입해서 실행(mutual exclusion) 가능한 영역
- mutual exclusion (상호 배제)
- 한 번에 하나의 프로세스/스레드가 critical section에서 실행할 수 있다.
- progress (진행)
- 아무도 critical section에 있지 않을 때, 들어가고자 하는 프로세스가 있으면 critical section에 들어가게 해주어야 한다.
- bounded waiting (한정된 대기)
- 하나의 프로세스/스레드가 critical section에 들어가기 위해서 무한정 기다리는 상황이 되면 안된다.
- 다른 프로세스들의 기아(Starvation)을 막기 위해서
Q. Race Condition(경쟁 상태)에 대하여 간단한 예시를 들어 설명해주세요.
통장 잔고를 예시로 들어보겠다. 2개의 쓰레드와 잔고라는 공유자원이 존재한다고 가정해보자.
잔고가 출금 금액보다 적을 경우에는 출금할 수 없다. 잔고에는 현재 5000원이 있다.
만일 쓰레드 1에서 5000원을 출금하기 위해 잔액을 먼저 조회한 후, 5000원 이상인 것을 확인했다.
그런데 이때 Context Switch가 발생하여 쓰레드 2로 교체 되었다.
쓰레드 2도 동일한 작업을 한다.
다행히 쓰레드 2에서는 출금 전 Context Switch가 발생하지 않아 출금을 마쳐 잔액은 0원이 되었다.
이후 Context Switch가 발생하여 다시 쓰레드 1로 교체되었다. 쓰레드1은 잔액조회까지 마쳤기 때문에 출금을 시도한다. 그러나, 잔액은 아까 쓰레드2의 작업으로 0원이 되어있어 출금을 하게 되면 0보다 작은 수가 된다.
Q. 뮤텍스와 세마포어 차이점에 대해 설명해주세요.
스핀락과 뮤택스와 달리 표현형이 정수형이다. 아래 value가 0,1,2, .... 가능하다.
이 점을 살려 하나 이상의 컴포넌트가 공유자원에 접근할 수 있도록 허용할 수 있다.
또한 Signaling 매커니즘으로 락을 걸지 않은 스레드도 signal을 통해 락을 해제할 수 있다.
상호 배제만 필요하면 뮤텍스를 권장하고, 작업 간의 실행 순서 동기화가 필요하면 세마포를 권장한다.
Q. 뮤텍스와 스핀락의 차이점에 대해 설명해주세요.
스핀락이 임계영역이 unlock(해제)되어 권한을 획득하기까지 Busy-Waiting 상태를 유지한다면,
뮤텍스는 Block(Sleep) 상태로 들어갔다 Wakeup 되면 다시 권한 획득을 시도한다.
Q. 뮤텍스가 스핀락보다 항상 좋은가요?
멀티 코어 환경이고, critical section에서의 작업이 컨텍스트 스위칭보다 더 빨리 끝난다면 스핀락이 뮤텍스보다 더 이점이 있다.
멀티프로세스, 스레드와 멀티 스레딩
Q. Process와 Thread의 차이를 설명해 보세요.
- 프로세스는 운영체제로 부터 자원을 할당받는 작업의 단위이다.
- 스레드는 할당 받은 자원을 이용하는 실행의 단위이고 프로세스 내에 여러개 생길 수 있다.
- 프로그램 하나가 프로세스이고, 그 안에서의 분기 처리가 스레드가 된다.
Q. Multi Process와 Multi Thread에 대해 설명해 주세요.
- multi process는 하나의 흐로그램을 여러개의 프로세스로 구성하여 각 프로세스가 하나의 작업(task)를 처리하는 것이다.
- 장점: 하나의 프로세스가 잘못되어도 프로그램은 동작함
- 단점: context switching 비용 발생
- multi thread는 프로그램을 여러개의 쓰레드로 구성하고 각 쓰레드가 작업를 처리하는 것
- 장점: 시스템 자원 소모 감소, 처리 비용 감소(실행 속도 향상), 프로세스간 통신보다 간단
- 단점: 디버깅 어려움, 동기화 이슈 발생, 하나의 쓰레드의 오류로 전체 프로세스에 문제 발생
Q. Thread Safe란 ?
thread safe란 것은 여러 thread가 동시에 사용되어도 안전한단 것을 뜻한다.
두 개 이상의 스레드가 race condition에 들어가거나 같은 객체에 동시에 접근해도 연산결과의 정합성이 보장될 수 있게끔 메모리 가시성이 확보된 상태를 의미한다.
시스템 콜
Q. 시스템 콜에 대해 설명하세요.
운영 체제의 커널이 제공하는 서비스에 대해, 응용 프로그램의 요청에 따라 커널에 접근하기 위한 인터페이스이다.
보통 C나 C++과 같은 고급 언어로 작성된 프로그램들은 직접 시스템 호출을 사용할 수 없기 때문에 API를 통해 시스템 호출에 접근하게 하는 방법이다.
Q. 운영체제의 Dual Mode 에 대해 설명해 주세요.
사용자와 운영체제는 시스템 자원을 공유한다.
그렇기에 사용자에게 제한을 두지 않으면 사용자가 메모리 내 주요 운영체제 자원을 망가뜨릴 위험이 생긴다.
운영체제의 원할한 작동과 기능을 위해서는 사용자의 시스템 자원 접근을 제한하는 보호 장치가 필수적이다.
이중 동작 모드는 사용자 모드와 커널 모드로 나뉘어진다.
사용자 모드에서 코드를 작성하고 프로세스를 실행하는 등의 행동을 할 수 있다.
커널 모드에서 시스템의 모든 메모리에 접근 가능하며 모든 종류의 CPU 명령을 실행할 수 있다.
Q. 시스템 콜의 유형에 대해 설명해 주세요
프로세스 제어, 파일 조작, 디바이스 조작, 정보 유지, 통신, 보호가 있다.
Q. 시스템 콜은 왜 필요할까요?
우리가 일반적으로 사용하는 프로그램은 '응용프로그램'이다.
유저레벨의 함수만으로는 많은 기능을 구현하기 힘들다. 따라서 커널의 도움이 필요하다.
커널(kernel)에 관련된 것은 커널 모드로 전환한 후에야, 해당 작업을 수행할 권한이 생긴다.
Q. 서로 다른 시스템 콜을 어떻게 구분하는지 설명해 주세요
- 커널은 내부적으로 각각의 시스템 콜을 구분하기 위해 기능별로 고유번호를 할당하고 그 번호에 해당하는 제어루틴을 커널 내부에 정의
- 커널은 요청받은 시스템 콜에 대응하는 기능번호를 확인 -> 그에 맞는 서비스 루틴 호출
TLB
Q. 전체적인 페이지 탐색과정을 설명해주세요.
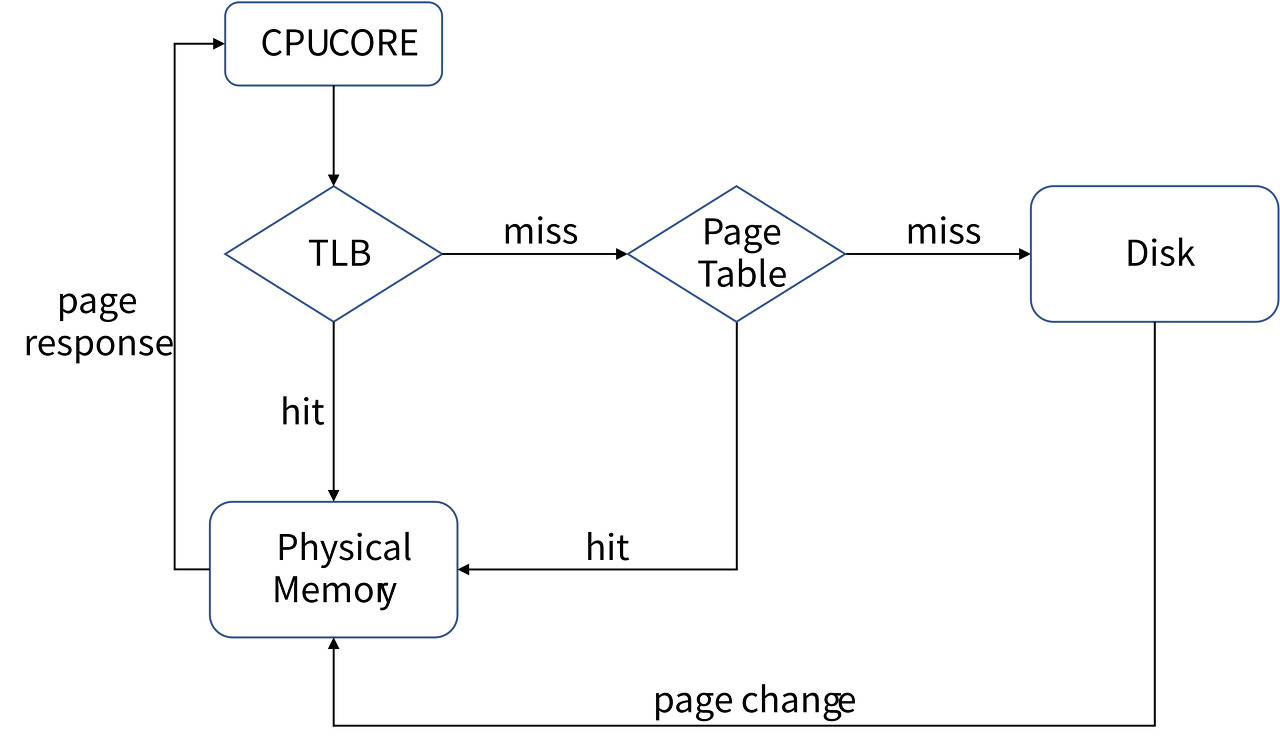
Q. 페이지 폴트(Page Fault)란 무엇인가?
프로세스가 페이지를 요청했을 때 해당 페이지가 메모리에 없을 경우를 뜻한다.
페이지 폴트가 발생하면 프레임(물리 메모리)을 새로 할당받아야한다.
프로세스가 해당 페이지를 사용할 수 있도록 스왑 영역에서 메인 메모리로 옮겨야 한다.
그리고 페이지 테이블을 재구성하고, 프로세스의 작업을 재 시작한다.
Q. TLB 히트, 미스, 페이지 히트 미스의 경우 속도 차이는?
TLB 히트로 즉시 페이지 로드가 가능한 경우 수십 클럭,
페이지 폴트의 경우에 비해 수십만 ~ 수백만 클럭이 소모되므로 수만 ~ 수십만 배의 속도 차가 발생 할 수 있다고 볼 수 있다.
Q. TLB가 나오게 된 배경은 무엇이고, TLB 개념에 대해 설명해주세요.
Paging 기법은 Paging Table을 기반으로 실제 메모리에 접근하기 때문에 메모리 낭비가 발생하고, 느리다.
이를 좀 더 빠르게 만들기 위해 TLB가 나오게 되었다.
Q. TLB가 메모리 성능을 어떻게 향상시키는지 TLB hit rate 와 Spatial Locality 개념과 연관지어 설명해주세요.
TLB에서 주소 변환이 성공하는 것을 TLB Hit이라고 합니다.
그리고 TLB Hit가 된 확률을 TLB hit rate라고 합니다.
모든 cache와 마찬가지로 TLB도 하나의 cache로써 spatial, temporal locality(공간, 시간 지역성)을 가집니다.
한 번 접근한 뒤에 다시 접근할 때는 이미 TLB에 모든 변환 정보가 존재하기 때문에 100%의 TLB hit rate로 주소 변환이 수행됩니다.
이러한Spatial Locality 특성 때문에 TLB hit rate를 높이게 되어 메모리 성능을 향상시킵니다.
Q. TLB를 사용할 때 Context Switching이 발생한다면 어떻게 해결하는 지 설명해주세요. (2가지 해결방안)
첫 번째 방법은 Context switch가 발생할 때 기존 프로세스의 주소변환 정보를 TLB에서 모두 지워버리는 것이다.
이를 flush라고 하는데, TLB의 주소 변환 정보중 valid 비트의 값을 0으로 초기화하여 TLB의 내용을 지우게 된다.
두 번째는 TLB에서 ASID(address space identifier)라는 정보를 추가한다.
어떤 프로세스의 정보인지 구별하기 위해 TLB에서 ASID를 제공한다.
이를 통해 프로세스마다 다른 ASID 정보를 저장하여 주소 변환을 성공적으로 수행할 수 있도록 한다.
Q. TLB에 저장 가능한 공간이 꽉 찼을 경우 새로운 프로세스가 실행된다면, 어떤 프로세스를 빼고 새로운 것을 넣어야 하는지 과정에 대해 설명해주세요. (TLB Replacement policy)
목표는 TLB miss rate를 최소화 하는 것(TLB hit rate를 향상시키는 것과 같은 말이다)
- LRU(Least-recently-used) : 최근에 사용하지 않는(예전에 사용하고 지금은 사용하지 않는) Process를 내보내는 방법이다.
- LRU는 Temporal Locality의 장점을 이용한다.
- Random policy : 이름 그대로 랜덤하게 제거하는 방법이다.
가상 메모리와 요구 페이징, 페이지 교체
Q. 가상메모리에 대해 설명해 주세요.
가상 메모리는 프로세스가 실제 메모리의 크기와 상관없이 메모리를 이용할 수 있도록 지원하는 기술
'Computer Science 📑' 카테고리의 다른 글
| [DB/데이터베이스] Clustering / Replication / Sharding (0) | 2023.02.13 |
|---|---|
| [DB/데이터베이스] RDB와 NoSQL의 Replicaiton / Clustering 방식 (0) | 2023.02.13 |
| [OS/운영체제] 메모리 계층(Memory Hierarchy) (4) | 2023.01.29 |
| [OS/운영체제] 운영체제란 (0) | 2023.01.28 |
| [OS/운영체제] CPU 스케줄링과 알고리즘 (1) | 2023.01.24 |




댓글